17.06.2024 | Michael Veser
Chat Applications Effectively Monitored by the SOC

Chat applications have become an essential part of our digital lives and offer a platform for real-time communication and interaction. At the same time, they have increasingly become targets for cyberattacks due to their widespread use and central importance. Attackers often try to trick chatbots into performing unwanted actions. This is done using techniques such as prompt injections or by manipulating the dialog. While classic protection mechanisms such as hardening and web application firewalls are used at the level of the overall system, specific preventive protection measures are available at the level of the language model.
These defensive measures include strategies such as blast radius reduction, which minimizes the impact of a successful prompt injection with the help of a defensive design, and input pre-processing, for example through paraphrasing. In addition, monitoring mechanisms such as guardrails, firewalls and filters help to detect attacks.
However, there is currently a lack of effective methods for monitoring the increased attack surface caused by the flexible input value of a “user prompt” in a meaningful way. The desired wide range of capabilities of chat applications in particular makes it difficult to distinguish between intended functions and exceeding the expected range of functions. Monitoring should not only refer to classic injections, but also alert in the event of unusual requests. However, we can also make use of these technical capabilities on the IT governance side to detect violations.
In this article, I present an approach that enables monitoring in the SOC on the basis of embedding and vectorization models.
Preliminary information
To understand the technology behind this detection model, you should first read my articles on embedding and tokenization. For additional background information, the article on fine-tuning and contextualization is also helpful.
Presentation of the approach
As part of my previous work on the security of GenAI applications, I have dealt in detail with the detection of attacks by and with GenAI technologies. I quickly realized that techniques that are also used for contextualization can be an effective approach for detecting anomalies. The development of the detection model comprises several phases:
Phase 1: Collection of log files
A critical first step in detecting and analyzing security threats in chat applications is the systematic collection of log files during the training phase.
Central logging of this data, for example with the help of a SIEM, serves several purposes: it not only serves as a basis for later analysis with regard to potential security breaches, but also helps to better understand user behaviour and optimize system performance. Each request is recorded in real time and stored centrally (e.g. in a SIEM). The stored information typically includes the text of the request and a timestamp. Depending on the target audience of the application and compliance requirements, plain text storage can be terminated after the training phase.
Phase 2: Training phase - embedding in a vector database
In the training phase of the chat application, the application is tested intensively by confronting it with both intended (normal) and potentially harmful (unintended) requests. Each of these requests is systematically integrated into a vector database. The aim of this phase is to create a robust database for the subsequent detection of anomalies.
There are two main approaches to training:
- Training exclusively with normal queries: Here, the model is trained exclusively with examples of normal, unsuspicious queries. The advantage of this approach is the focus on recognizing typical, safe patterns of user behavior. A One-Class Support Vector Machine (SVM), which is trained to recognize everything that does not correspond to the “normal” pattern as an anomaly, is particularly suitable for classifying such data.
2 Training with normal and unwanted queries: This approach deliberately includes malicious queries in the training to prepare the model for a wider range of inputs. This enables a more sophisticated classification and improves the accuracy of anomaly detection. Methods such as k-nearest neighbors (kNN), cosine similarity or a classical SVM can be used here to distinguish between normal and malicious queries based on the embedded vectors.
The choice of training approach and classification model has a significant influence on how effectively the system will be able to distinguish real threats from regular user requests. Particular care must be taken to ensure that the model is both highly sensitive in detecting actual threats and has a low rate of false positives so as not to compromise the user experience.
Phase 3: Test phase
After preparing the vector database with the training data from phase 2, the application can be further evaluated by testing with simulated attacks and normal requests. Each new request is temporarily inserted into the vector database and checked for similarity with existing data sets. Based on this analysis, an anomaly probability is calculated, which can be transmitted directly to the Security Operations Center (SOC ).
Illustration
A visualization of the vector space should now provide you with a more tangible insight into the model described. For testing purposes, we are using a data set with several hundred requests to a chat system, half of which have malicious content. The training data is shown in dark green and dark red, while the lighter version shows the test data. The embedding is done with the so-called “DistilBERT” embedding model, which was optimized for this purpose.
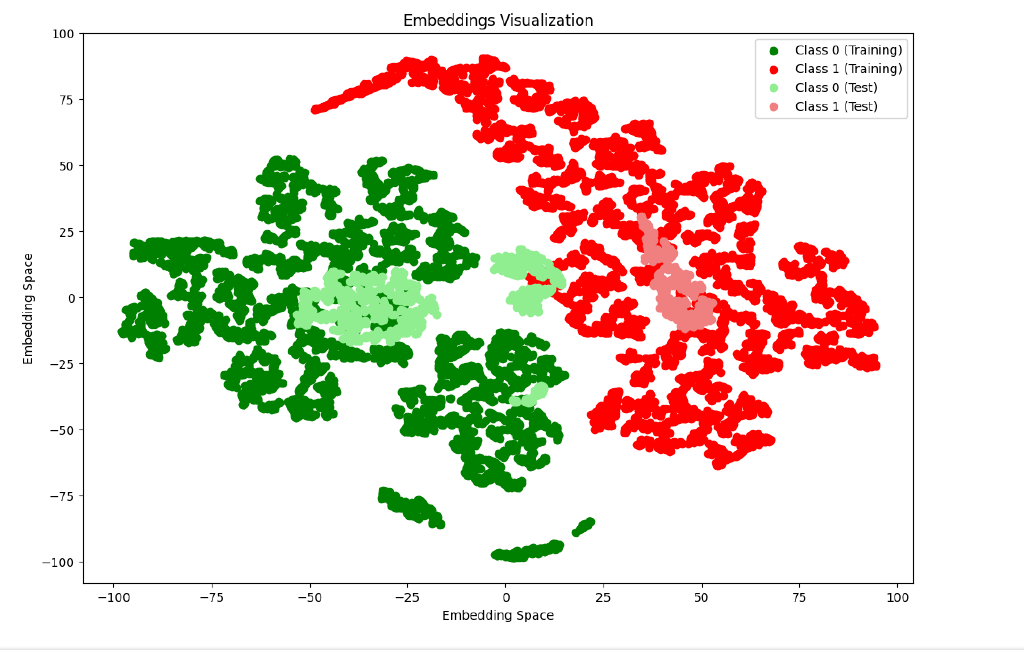
Conclusion and result
Despite the predominantly good results in the test run, we should not underestimate the requirements for the transition to a productive environment. Depending on the size of the application, an incorrectly dimensioned embedding model can become a performance bottleneck. Nevertheless, this example shows how a core competence of language models, the recognition of content from unstructured input values, can also be used sensibly for defense purposes.
Cybersecurity Artificial Intelligence
