10.06.2024 | Michael Veser
How you can Incorporate your Company's own Data into a Generative AI Application

This article explains the technical basics of generative AI systems. It is intended to provide a better understanding of our articles on security issues relating to the use of AI systems.
Even if the public models such as ChatGPT already offer a wide range of knowledge, the practical benefits can be greatly increased by using the company’s own data. For example, you can verify information at any time by outputting the original source and also feed in up-to-date information.
For the subsequent development of an intelligent Large Language Model (LLM), which is to have access to its own database, it is first important to understand the type of data provision. You can read my article on embedding and tokenization for more information. In addition to the methodology described on the following pages, established databases can also be used for so-called contextualization without any problems. In this case, however, the data records must be available in a structured form. In most companies, however, a large part of the data is not sufficiently structured in the form of documents, e-mails, text files or tables. For this reason, ingestion using a traditional database schema such as SQL would be a time-consuming process.
Option 1: Fine-tuning
Fine-tuning of Large Language Models is a specialized process in which an already pre-trained model is further trained to adapt it to the specific needs and data of a company. This is done by introducing company-specific data into the training phase of the model, which enables the model to learn the company’s linguistic patterns, jargon and specific contexts. The process is aimed at general formulation skills rather than day-to-day data.
Functionality
During fine-tuning, a basic model that has already been trained on a large generic data set is additionally trained with a smaller, specific data set. This specific data set consists of texts and data that are relevant to the company. The fine-tuning process adjusts the so-called weights and parameters of the model so that it can react better to the new data and associated tasks, such as classifying documents or answering specific questions.

Advantages
- Specificity: through fine-tuning, the model can better understand and generate specific terminologies and usage contexts prevalent in an organization.
- Efficiency: a fine-tuned model can respond to specific queries more accurately and relevantly, which can increase user satisfaction and operational efficiency.
Disadvantages
- Costs and resources: Fine-tuning requires computationally intensive resources, at least temporarily, and can be expensive, especially for very large models.
- Overfitting: There is a risk that the model is “overtrained” on the specific training data set and thus loses its ability to respond effectively to more general or divergent data.
- Maintenance: Updating and adapting the model on a regular basis requires continuous effort and resources, especially when the data or requirements of the company change.
Option 2: Contextualization
Contextualization is a method of improving the relevance and precision of Large Language Model responses by taking a specific context into account when processing queries. This technique is used in particular to increase the flexibility of the model when answering queries without requiring changes to the underlying model parameters.
Functionality
During contextualization, the text of a user request is transmitted to the model together with additional contextual information. This context can be in the form of previous conversations, relevant documents or specially selected data that supports the query. A special form of contextualization uses vector databases to increase relevance. Here, each query is converted into a vector and compared against a database of vectors that already represent known and relevant information. These vectors could, for example, represent documents, previous queries or specialized information. The system then searches for the most similar vectors in the database and uses the associated information to interpret and answer the query in a context that is better suited to the user’s specific needs. The results are then transferred to the actual language model together with the user’s original query.
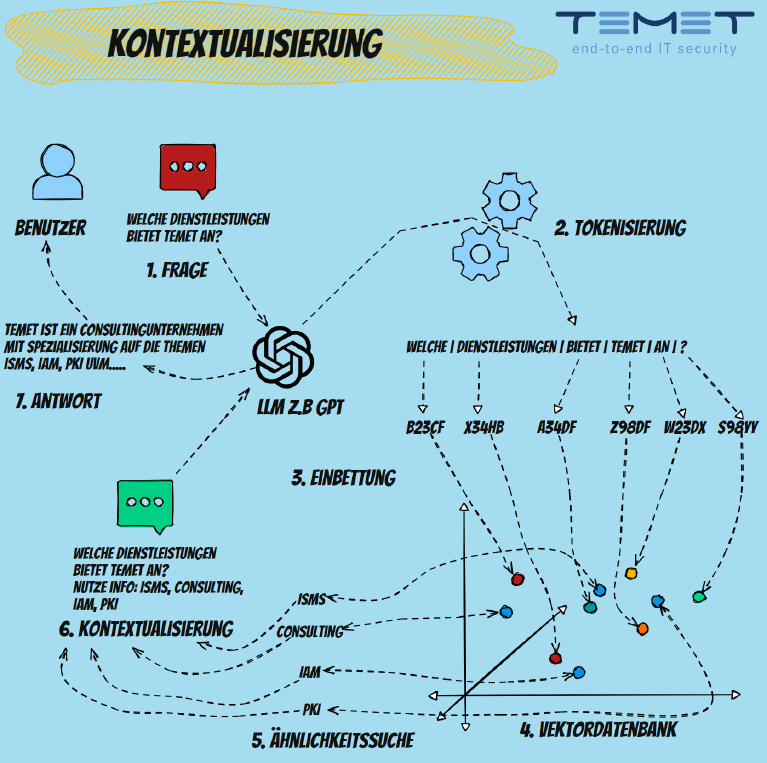
Advantages
- Increased relevance: by adding specific context, answers can be made more precise and informative.
- Adaptability: contextualization makes it possible to adapt the model to different situations and requirements without the need for retraining.
- Fast implementation: contextualization can be implemented quickly as it is mainly based on editing input data and not on changing the model itself.
Disadvantages
- Data dependency: the effectiveness of contextualization depends heavily on the quality and relevance of the context data used.
- Complexity of data management: managing and updating the vector database can be complex and time-consuming.
- Limited control over model bias: Since the base model remains unchanged, existing biases or inadequacies of the model cannot be directly addressed by contextualization.
Conclusion and comparison
Fine-tuning and contextualization are both effective methods to optimize the performance of Large Language Models (LLM), but they target different needs and applications.
Fine-tuning is particularly suitable for companies that want to adapt their models to specific tasks and general formulation capabilities. It enables a deep customization of the model to the unique linguistic patterns and terminology that prevail within the company or a specific industry. This form of customization is permanent and changes the basic structure of the model, which improves the performance of specialized tasks. However, this requires significant resources for training and maintenance and carries the risk of overfitting, which can limit the model’s ability to respond to new, unforeseen requests.
In contrast, contextualization offers a flexible and less resource-intensive method of improving performance. It makes it possible to integrate up-to-date information into the model responses without changing the base model. This technique is ideal for dynamic use cases where frequently updated or changing information is required. It also provides an interface to peripheral systems, as the context variable can also be used to integrate daily updated results from API queries or classic databases. In addition, the source information used for contextualization increases the transparency and credibility of the generated content.
In summary, fine-tuning is best suited to scenarios where a high degree of specialization and adaptation to well-defined tasks is required, while contextualization offers advantages in environments that require rapid adaptability to current events and high transparency of information sources. Both approaches complement each other and can be selected depending on the specific requirements and framework conditions of the area of application.
