
11.09.2024|
Markus Günther
|
Artikel
17.06.2024
|Michael Veser
|Artikel

Chat-Applikationen sind zu einem wesentlichen Bestandteil unseres digitalen Lebens geworden und bieten eine Plattform für Echtzeitkommunikation und Interaktion. Gleichzeitig sind sie aufgrund ihrer weiten Verbreitung und zentralen Bedeutung zunehmend Ziele für Cyberangriffe geworden. Angreifer versuchen häufig, die Chatbots zu ungewollten Aktionen zu verleiten. Dies geschieht durch Techniken wie Prompt Injections oder durch die Manipulation der Dialogführung. Während auf der Ebene des Gesamtsystems klassische Schutzmechanismen wie Härtung und Web Application Firewalls zur Anwendung kommen, bieten sich auf der Ebene des Sprachmodells spezifische präventive Schutzmassnahmen an.
Zu diesen Verteidigungsmassnahmen zählen Strategien wie die Reduzierung des Schadensradius (Blast Radius Reduction), durch die der Einfluss einer erfolgreichen Prompt-Injektion mithilfe eines defensiven Designs minimiert wird, sowie das Vorverarbeiten von Eingaben (Input Pre-Processing), etwa durch Paraphrasierung. Zusätzlich helfen Überwachungsmechanismen wie Guardrails, Firewalls und Filter dabei, Angriffe zu erkennen.
Aktuell fehlt es jedoch an effektiven Methoden, um die erhöhte Angriffsfläche durch den flexiblen Eingabewert einer «User-Prompt» sinnvoll zu überwachen. Gerade die erwünschte breite Palette an Fähigkeiten von Chat-Applikationen erschwert es, zwischen gewollter Funktion und einer Überschreitung des erwarteten Funktionsumfangs zu unterscheiden. Die Überwachung soll sich nicht nur auf klassische Injections beziehen, sondern auch im Falle ungewöhnlicher Anfragen alarmieren. Wir können uns jedoch auch auf Seiten der IT-Governance eben diese technischen Fähigkeiten zu Nutze machen, um Verstösse zu erkennen.
In diesem Artikel stelle ich Ihnen einen Ansatz vor, der auf Basis von Einbettungs- und Vektorisierungsmodellen eine Überwachung im SOC möglich macht.
Um die Technologie hinter diesem Detektionsmodell zu verstehen, sollten Sie zunächst meine Artikel zur Einbettung und Tokenisierung lesen. Als zusätzliche Hintergrundinformation ist ausserdem der Artikel über Feintuning und Kontextualisierung hilfreich.
Im Rahmen meiner bisherigen Arbeit rund um die Sicherheit von GenAI-Applikationen habe ich mich eingehend mit der Erkennung von Angriffen durch und mit GenAI-Technologien auseinandergesetzt. Dabei ist mir schnell aufgefallen, dass Techniken, die auch zur Kontextualisierung genutzt werden, einen effektiven Ansatz zur Erkennung von Anomalien darstellen können. Die Entwicklung des Detektionsmodells umfasst mehrere Phasen:
Ein kritischer erster Schritt in der Erkennung und Analyse von Sicherheitsbedrohungen in Chat-Applikationen ist die systematische Sammlung von Logdateien während der Trainingsphase.
Das zentrale Logging dieser Daten, beispielsweise mit Hilfe eines SIEM, erfüllt mehrere Zwecke: Es dient nicht nur als Grundlage für die spätere Analyse im Hinblick auf potenzielle Sicherheitsverletzungen, sondern hilft auch dabei, das Verhalten der Nutzer besser zu verstehen und die Systemleistung zu optimieren. Jede Anfrage wird dazu in Echtzeit erfasst und zentral (beispielsweise in einem SIEM) gespeichert. Zu den gespeicherten Informationen gehören typischerweise der Text der Anfrage und ein Zeitstempel. Die Klartextspeicherung kann je nach Zielpublikum der Applikation und Compliance-Anforderungen nach der Trainingsphase beendet werden.
In der Trainingsphase der Chat-Applikation wird die Applikation intensiv getestet, indem sie sowohl mit beabsichtigten (normalen) als auch mit potenziell schädlichen (ungewollten) Anfragen konfrontiert wird. Jede dieser Anfragen wird systematisch in eine Vektordatenbank integriert. Ziel dieser Phase ist es, eine robuste Datenbasis zur späteren Detektion von Anomalien zu schaffen.
Es gibt zwei Hauptansätze für das Training:
Training ausschliesslich mit normalen Anfragen: Hierbei wird das Modell ausschliesslich mit Beispielen von normalen, unverdächtigen Anfragen trainiert. Der Vorteil dieses Ansatzes liegt in der Fokussierung auf das Erkennen typischer, sicherer Muster des Benutzerverhaltens. Für die Klassifikation solcher Daten eignet sich besonders eine One-Class Support Vector Machine (SVM), die darauf trainiert ist, alles, was nicht dem «normalen» Muster entspricht, als Anomalie zu erkennen.
Training mit normalen und ungewollten Anfragen: Dieser Ansatz bezieht bewusst schädliche Anfragen mit in das Training ein, um das Modell auf eine breitere Palette von Eingaben vorzubereiten. Das ermöglicht eine differenziertere Klassifikation und verbessert die Genauigkeit bei der Erkennung von Anomalien. Methoden wie k-Nächste-Nachbarn (kNN), Kosinusähnlichkeit oder eine klassische SVM können hier verwendet werden, um auf Basis der eingebetteten Vektoren zwischen normalen und schädlichen Anfragen zu unterscheiden.
Die Wahl des Trainingsansatzes und des Klassifikationsmodells hat einen wesentlichen Einfluss darauf, wie effektiv das System in der Lage sein wird, echte Bedrohungen von regulären Nutzeranfragen zu unterscheiden. Dabei muss besonders darauf geachtet werden, dass das Modell sowohl hochsensibel in der Erkennung tatsächlicher Bedrohungen ist als auch eine geringe Rate an falsch-positiven Ergebnissen aufweist, um die Nutzererfahrung nicht zu beeinträchtigen.
Nach der Vorbereitung der Vektordatenbank mit den Trainingsdaten aus Phase 2 kann die Anwendung durch das Testen mit simulierten Angriffen und normalen Anfragen weiter evaluiert werden. Jede neue Anfrage wird temporär in die Vektordatenbank eingefügt und auf Ähnlichkeit mit bestehenden Datensätzen geprüft. Basierend auf dieser Analyse wird eine Anomalienwahrscheinlichkeit berechnet, die unmittelbar an das Security Operations Center (SOC ) übermittelt werden kann.
Eine Visualisierung des Vektorraums soll Ihnen nun einen besser greifbaren Einblick in das beschriebene Modell liefern. Zum Testen nutzen wir hier einen Datensatz mit mehreren hundert Anfragen an ein Chatsystem, wovon die Hälfte schadhaften Inhalt aufweisen. Jeweils in dunkelgrün und dunkelrot sind die Trainingsdaten zu sehen, während die jeweils hellere Variante die Testdaten zeigt. Die Einbettung erfolgt mit dem sogenannten «DistilBERT» Einbettungsmodell, welches für diesen Einsatzzweck optimiert wurde.
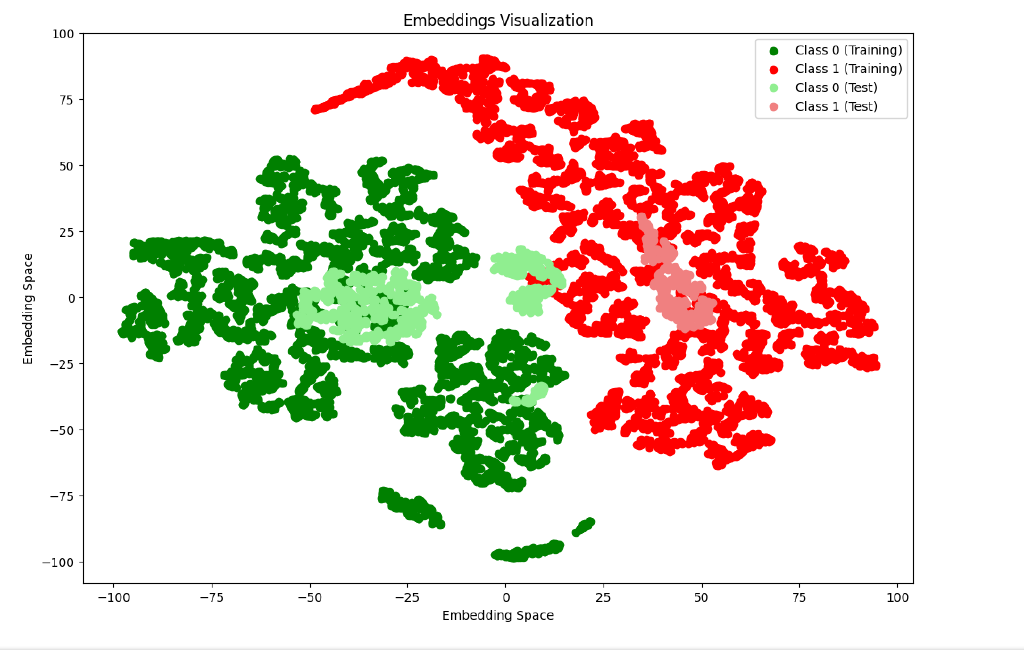
Trotz der vorwiegend guten Ergebnisse im Testdurchlauf sollten wir die Ansprüche für den Übergang in eine produktive Umgebung nicht unterschätzen. Je nach Grösse der Applikation kann ein falsch dimensioniertes Einbettungsmodell zu einem Flaschenhals in der Performance werden. Dennoch zeigt dieses Beispiel, wie eine Kernkompetenz der Sprachmodelle, die Erkennung von Inhalten aus unstrukturierten Eingabewerten, auch zu Verteidigungszwecken sinnvoll eingesetzt werden kann.

Michael Veser ist Cybersecurity-Experte mit 8 Jahren Erfahrung als Security Engineer und Berater. Er berät Kunden in den Bereichen Web Application Security, PKI, SOC und Künstlicher Intelligenz.
