10.06.2024 | Michael Veser
Wie Sie unternehmenseigene Daten in eine generative AI-Applikation einbringen können

Dieser Artikel erläutert technische Grundlagen von generativen AI Systemen. Er dient dem besseren Verständnis unserer Artikel zu Security Fragestellungen rund um den Einsatz von AI Systemen.
Auch wenn die öffentlichen Modelle wie ChatGPT bereits ein grosses Wissensspektrum bieten, kann durch den Einsatz von unternehmenseigenen Daten der praktische Nutzen stark erhöht werden. So können Sie durch die Ausgabe der Ursprungsquelle jederzeit Informationen verifizieren und zudem tagesaktuelle Informationen einspeisen.
Für den späteren Aufbau eines intelligenten Large Language Models (LLM), welches Zugriff auf einen eigenen Datenbestand erhalten soll, ist es zunächst wichtig, die Art der Datenbereitstellung zu verstehen. Hierzu können Sie meinen Artikel zur Einbettung und Tokenisierung lesen. Neben der auf den nächsten Seiten beschriebenen Methodik können auch etablierte Datenbanken zur sogenannten Kontextualisierung problemlos verwendet werden. Hier müssen die Datensätze jedoch in strukturierter Form vorliegen. In den meisten Unternehmen liegt ein Grossteil der Datenbestände jedoch nicht ausreichend strukturiert in Form von Dokumenten, E-Mail, Textdateien oder Tabellen vor. Aus diesem Grund wäre die Aufnahme mittels eines traditionellen Datenbankschemas wie SQL ein aufwendiger Prozess.
Möglichkeit 1: Feintuning
Feintuning von Large Language Models ist ein spezialisierter Prozess, bei dem ein bereits vortrainiertes Modell weiter trainiert wird, um es auf die spezifischen Bedürfnisse und Daten eines Unternehmens anzupassen. Dies geschieht durch das Einbringen von unternehmensspezifischen Daten in die Trainingsphase des Modells, was dem Modell ermöglicht, die sprachlichen Muster, Fachjargon und spezifische Kontexte des Unternehmens zu lernen. Der Prozess zielt eher auf generelle Formulierungsfähigkeiten als auf tagesaktuelle Daten ab.
Funktionsweise
Beim Feintuning wird ein Basismodell, das bereits auf einem grossen generischen Datensatz trainiert wurde, zusätzlich mit einem kleineren, spezifischen Datensatz trainiert. Dieser spezifische Datensatz besteht aus Texten und Daten, welche für das Unternehmen relevant sind. Der Feintuning-Prozess passt die sogenannten Gewichte und Parameter des Modells so an, dass es besser auf die neuen Daten und damit verbundenen Aufgaben reagieren kann, wie etwa die Klassifizierung von Dokumenten oder das Beantworten spezifischer Fragen.

Vorteile
- Spezifität: Durch Feintuning kann das Modell spezifische Terminologien und Nutzungskontexte, die in einem Unternehmen vorherrschen, besser verstehen und generieren.
- Effizienz: Ein feingetuntes Modell kann auf spezifische Anfragen präziser und relevanter antworten, was die Benutzerzufriedenheit und die operationelle Effizienz steigern kann.
Nachteile
- Kosten und Ressourcen: Feintuning erfordert zumindest temporär rechenintensive Ressourcen und kann teuer sein, besonders bei sehr grossen Modellen.
- Overfitting: Es besteht die Gefahr, dass das Modell auf den spezifischen Trainingsdatensatz «übertrainiert» wird und dadurch seine Fähigkeit verliert, auf allgemeinere oder abweichende Daten effektiv zu reagieren.
- Wartung: Das Modell regelmässig zu aktualisieren und anzupassen, erfordert kontinuierlichen Aufwand und Ressourcen, besonders wenn sich die Daten oder Anforderungen des Unternehmens ändern.
Möglichkeit 2: Kontextualisierung
Kontextualisierung ist eine Methode zur Verbesserung der Relevanz und Präzision der Antworten von Large Language Models, indem ein spezifischer Kontext bei der Verarbeitung von Anfragen berücksichtigt wird. Diese Technik wird insbesondere genutzt, um die Flexibilität des Modells bei der Beantwortung von Anfragen zu erhöhen, ohne dass Änderungen an den zugrunde liegenden Modellparametern erforderlich sind.
Funktionsweise
Bei der Kontextualisierung wird der Text einer Benutzeranfrage zusammen mit zusätzlichen Kontextinformationen an das Modell übermittelt. Dieser Kontext kann in Form von vorangegangenen Konversationen, relevanten Dokumenten oder speziell ausgewählten Daten, die die Anfrage unterstützen, vorliegen. Eine besondere Form der Kontextualisierung nutzt Vektordatenbanken, um die Relevanz zu steigern. Dabei wird jede Anfrage in einen Vektor umgewandelt und gegen eine Datenbank von Vektoren abgeglichen, die bereits bekannte und relevante Informationen repräsentieren. Diese Vektoren könnten beispielsweise Dokumente, frühere Anfragen oder spezialisierte Informationen abbilden. Das System sucht dann nach den ähnlichsten Vektoren in der Datenbank und nutzt die dazugehörigen Informationen, um die Anfrage in einem Kontext zu interpretieren und zu beantworten, der besser auf die spezifischen Bedürfnisse des Nutzers abgestimmt ist. Die Ergebnisse werden im Anschluss gemeinsam mit der ursprünglichen Anfrage des Benutzers an das eigentliche Sprachmodell übergeben.
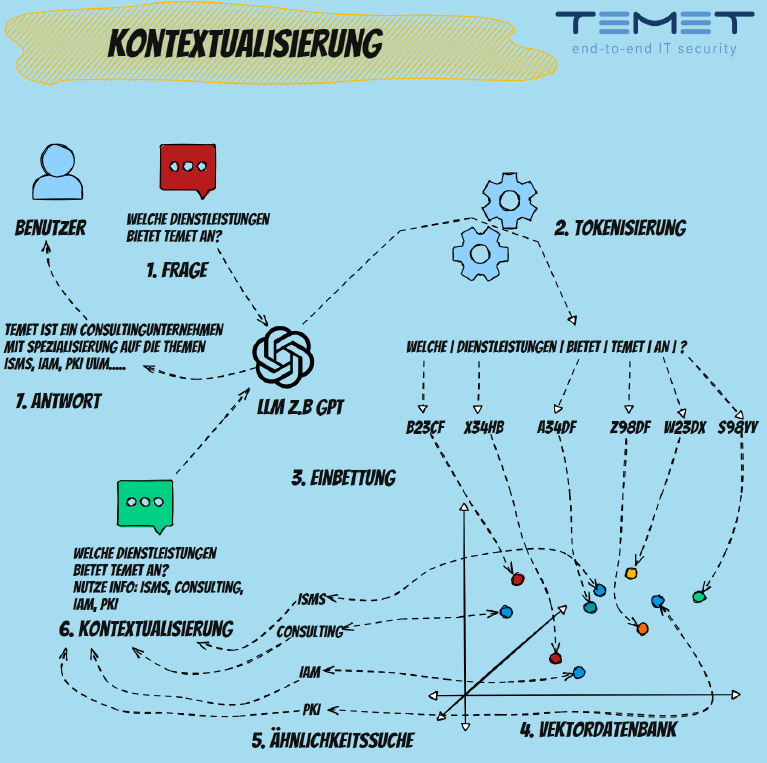
Vorteile
- Relevanzsteigerung: Durch das Hinzufügen von spezifischem Kontext können Antworten präziser und informativer gestaltet werden.
- Anpassungsfähigkeit: Kontextualisierung ermöglicht es, das Modell an unterschiedliche Situationen und Anforderungen anzupassen, ohne dass ein Neutraining erforderlich ist.
- Schnelle Implementierung: Kontextualisierung kann schnell umgesetzt werden, da sie hauptsächlich auf der Bearbeitung von Eingabedaten basiert und nicht auf der Änderung des Modells selbst.
Nachteile
- Datenabhängigkeit: Die Effektivität der Kontextualisierung hängt stark von der Qualität und Relevanz der verwendeten Kontextdaten ab.
- Komplexität der Datenverwaltung: Das Verwalten und Aktualisieren der Vektordatenbank kann komplex und aufwendig sein.
- Limitierte Kontrolle über Modellbias: Da das Basismodell unverändert bleibt, können bestehende Verzerrungen oder Unzulänglichkeiten des Modells durch Kontextualisierung nicht direkt adressiert werden.
Fazit und Vergleich
Feintuning und Kontextualisierung sind beides effektive Methoden, um die Leistung von Large Language Models (LLM) zu optimieren, sie zielen allerdings auf unterschiedliche Bedürfnisse und Anwendungen ab.
Feintuning ist besonders geeignet für Unternehmen, die ihre Modelle an spezifische Aufgaben und die generelle Formulierungsfähigkeit anpassen möchten. Es ermöglicht eine tiefgreifende Anpassung des Modells an die einzigartigen sprachlichen Muster und Fachterminologien, die innerhalb des Unternehmens oder einer spezifischen Branche vorherrschen. Diese Form der Anpassung ist dauerhaft und verändert die Grundstruktur des Modells, was die Performance spezialisierter Aufgaben verbessert. Allerdings erfordert dies signifikante Ressourcen für das Training und die Wartung und birgt das Risiko von Overfitting, was die Fähigkeit des Modells einschränken kann, auf neue, unvorhergesehene Anfragen zu reagieren.
Im Gegensatz dazu bietet die Kontextualisierung eine flexible und weniger ressourcenintensive Methode zur Leistungssteigerung. Sie ermöglicht es, tagesaktuelle Informationen in die Modellantworten zu integrieren, ohne das Basismodell zu verändern. Diese Technik ist ideal für dynamische Anwendungsfälle, in denen häufig aktualisierte oder wechselnde Informationen benötigt werden. Sie bietet auch eine Schnittstelle zu Umsystemen, da durch die Kontextvariable auch tagesaktuelle Ergebnisse von API-Abfragen oder klassischen Datenbanken integriert werden können. Darüber hinaus erhöhen die bei der Kontextualisierung verwendeten Quellenangaben die Transparenz und Glaubwürdigkeit der generierten Inhalte.
Zusammengefasst ist Feintuning am besten für Szenarien geeignet, in denen ein hohes Mass an Spezialisierung und Anpassung an fest definierte Aufgabenstellungen erforderlich ist, während Kontextualisierung Vorteile in Umgebungen bietet, die eine schnelle Anpassungsfähigkeit an aktuelle Ereignisse und eine hohe Transparenz der Informationsquellen erfordern. Beide Ansätze ergänzen sich und können je nach spezifischen Anforderungen und Rahmenbedingungen des Einsatzbereiches gewählt werden.
